Our first SlideWiki developers meeting took place July 21-22 in Amsterdam, with 17 SlideWiki-developers from all over Europe attending.
Day 1
Warm-up programming game: the main idea was to warm up developers by hacking some parts of the existing code base (not to be very competitive but more fun!). To fulfil the requested tasks, people needed to understand different parts of the architecture (e.g. ReactJS, Flux Data Flow and Fluxible). You can play the game yourself by cloning the repository from GitHub.
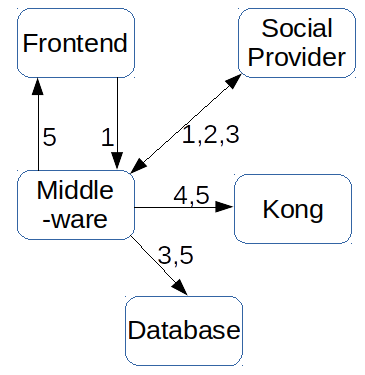
Quick overview of communication in system : This presentation showed developers how different parts of the system work together and how data flows between those parts using an example scenario. See the presentation here or below:


Discussion on version management: We agreed on a minor modification of our current approach.
Pair-programming on development tasks and deck-microservice: A large part of the Hackathon was reserved for development. Being all together we could effectively use each other's expertise, and help each other out by programming in pairs, or even by gathering with four or five developers to work on a task or problem. The close collaboration accelerated development and allowed us to identify many solutions to problems and new challenges that we had to discuss.
Day 2
Core tasks for September release: We discussed the resource planning for our September release. We have to work on development tasks that are interdependent, and the resource planning allows us to take these dependencies into account, together with the availability of developers during holiday-season.
Pair programming on implementing deck-services and user management: This was one of the most productive sessions where we started to further implement the main deck-service API and user management services in the SlideWiki system.

Discussing the storyboard workflow (order of pages) for core development tasks: In a break-out session several developers discussed how user management pages should be ordered and presented to the end-users, and what the required changes in the current user interface should be.
Developers Meeting: Our weekly developer meeting was on location this time. We had several useful activities:
- Scrum stand-up (what is everyone working on? how did it go? what will we do next?)
- Scrum demo (presentation of work done) and
- Scrum retrospective (feedback from team-members on process, tools, people, etc.).
In summary: we got many things done.
Looking forward to next time.

